2024. 12. 16. 17:22ㆍ메타코드/정보처리산업기사

강의목차

이제 슬슬 정보처리기사 필기 신청기간이 언젠지 뜨기 시작했다...
메타코드에서 제공해주는 강의를 한 번 완강하고 또 다시 한 번 들을 수 있도록
시간분배를 잘해야겠다.
강의 정리 및 필기
♣ 관계 데이터베이스 모델

관계데이터모델
-데이터를 테이블 형식으로 정리하여 저장하고, 각 테이블이 서로 관계를 맺도록 하는 데이터베이스 모델
-Codd가 제안했으며 데이터베이스 관리 시스템(DBMS)의 이론적 기초가 됨
주요구성요소
-릴레이션,튜플,속성 등
릴레이션
-행과 열로 구성된 테이블
행->튜플
열->애트리뷰트, 속성
시간에 따라 변함
릴레이션에 포함된 튜플 사이에는 순서가 없다(애트리뷰트도)
릴레이션 수->테이블 수
튜플
-렐레이션의 행
-튜플의 수를 카디널리티(몇개의데이터행이 있는지)라고 함
애트리뷰트
-릴레이션의 열=특성=속성=필드
-개체의 특성
-데이터베이스를 구성하는 가장 작은 논리적 단위
-애트리뷰트 수를 차수라고 함

김철수라는 직원의 정보는 하나의 튜플로 표현이 되고
이름이나 부서명은 각각의 애트리뷰트로 표현됨
관계대수
-관계형 데이터베이스를다루는 수학적 연산 체계, 데이터베이스 검색에 대한 이론적 기반이 됨
특징
-정차적 언어
-릴레이션 조작을 위한 연산의 ㅂ집합, 피연산자와 결과가 모두 릴레이션
-질의에 대한 해를 구하기 위해 수행해야 할 연산의 순서를 명시
-일반 집합 연산과 순수 관계 연산으로 구분
일반집합
-합집합
-교집합
-차집합
-카르테시안 곱 : 각 릴레이션의모든 튜플 쌍을 조합하는 새로운 릴레이션을 생성. 카티션 프로덕트의 결과로 생긴 릴레이션의 카디널리티는 각 릴레이션 카디널리티의 곱이 됨.
순수관계연산자
-셀렉트 : 릴레이션에서 특정조건을 만족하는 튜플을 선택. SELECT WHERE
-프로젝트 : 특정 속성만을 추출. SELECT
-조인 : 두 릴레이션이 공통으로 가진 속성을 이용해 두 릴레이션을 결합해 하나의 새로운 릴레이션을 만듦.
-디비전 : 특정 릴레이션의 모든 튜플과연관된 튜플을 반환. R%S->S에 있는 모든 튜플과 연관된 R을 반환
관계해석
-관계형 대이터베이스에서 '무엇을' 원하ㅈ는지 표현하는 비절차적 질의 언어
-사용자가 원하는 결과를 선언적으로 명시


관계 대수 vs 관계 해석
-관계 대수는 절차적, 관계 해석은 비절차적(선언적)
-관계 대수는 데이터를 어떠헥 처리할 지 명시적으로 정의
-관계 해석은 무엇을 원하는 지 명시
SQL은 둘 다 포함

시스템 카탈로그
-DBMS가 스스로 생성하고 유지하는 데이터베이스 내의 특별한 테이블 집합체
-메타데이터를 유지 관리
-사용자가 SQL문으로 변화를 주명 시스쳄이 자동으로 갱신
-데이터 사전이라고도 함
♣ 데이터 모델링 및 설계
데이터모델
-데이터베이스시스템이 데이터를 체계적으로 관리하고 조작할 수 있도록 하는 대념적인 프레임워크
-개념적,논리적 ,물리적모델로 설명 가능
-데이터 모델에는 구조,연산,제약조건이 표시되어야 함
데이터 베이스의 설계 순서
요구사항 분석-개념적설계-논리적설계-물리적설계-구현
데이터모델의 개념적 설계
-데이터베이스의 전반적인 구조 정의, 데이터의 내용과 관계를 면확히 정리하는 단계
-데이터베이스가 처리할주요 대체(엔티티)와 이들 간의 관계를 정의
-개체-관계(E-R)다이러그램을 만들 수 있음.구조 한눈에 파악
-논리적 설계 단계의 앞 단계

E-R 다이러그램
-개체: 사각형
-속성: 차원형
-다중값속성: 이중타원
-관계:마름모
-솬게-속성 연걸:선
데이터 모델의 논리적 설계
-개념적 설계를 바탕으로 데이터 베이스를 논리적 구조로 변환
-트랜잭션 인터페이스 설계
-스키마의 평가 및 정제
데이터 모델의 물리적 설계
-논리적 설계를 기반으로 데이터 저장 방식을 효율적인 방식으로 최적화
-저장 레코드의 형식, 순서,데이터값의 분포, 접근경로,접근빈도와 같은 정보를 사용하여 설계
-레코드 집중의 분석 및 설계
이상
-릴레이션 조작 시 데이터들이 불필요하게 중복되어 예기치 않게 발생하는 곤란한 현상
DB에서 각종 데이터 처리 연산 수행시 발생할 수 있는 이상
-삽입이상
-삭제이상
-갱신이상
정규화
-데이터베이스 설계 시 데이터를 구조화하여 중복을 최소화하고 데이터 무결성을 보장하는 과정
정규화의 장점
-데이터 구조의 안정성을 최대화함
-중복을 최소화하여 삽입,삭제 ,갱신 이상의 발생을 방지
-데이터 삽입 시 릴레이션을 재구성할 필요를 줄임
-테이블 불일치의 위험 최소화
-효과적인 검색 알고리즘을 생성할 수 있음
제1정규형

-어떤 릴레이션에 속한 모든 도메인이 원자값만으로 되어 있음
-각 컬럼에는 단일 값만 포함되어야 함
-데이터 중복을 줄이고 데이터처리의 일관성을 높힌다.
제2정규형

부분함수 종속성->교수명은 과목ID만 알아도 알 수 있어서 기본키의 일부에만 종속된 상황.
교수명을 별도의 테이블로 분리하여 과목ID와 교수이름만 따로 관리하면 2차 정규화를 만족하게 됨.
제3정규형

이행적 함수 족속 관계: A->B이고 B->C일 때, A->C를 만족하는 관계
직원ID가 부서ID를 결정하고, 부서ID는 부서명을 결정하므로 직원ID->부서명이라는 이행함수 종속성 발생
부서명을 별도의 테이블로 분리아혀 이행함수 종속성을 제거
Boyce codd 정규화(BCNF)

테이블을 분리하면 후보키가 아닌 함수 종속이 사라져 BCNF를 만족
제4정규형

101학생을 (영어,일본어)를 할 수 있고 취미는 (축구,농구)
언어와 취미 모두 학생ID에 의존적이지만, 언어와 취미는 독립적
한 항목이 여러 개의다른 항목과 각각 독립적으로 연결되어 있는 관계를 다치 종속성이라 함
다치 종속성을 제거함으로써 4NF를 만족
제5정규형
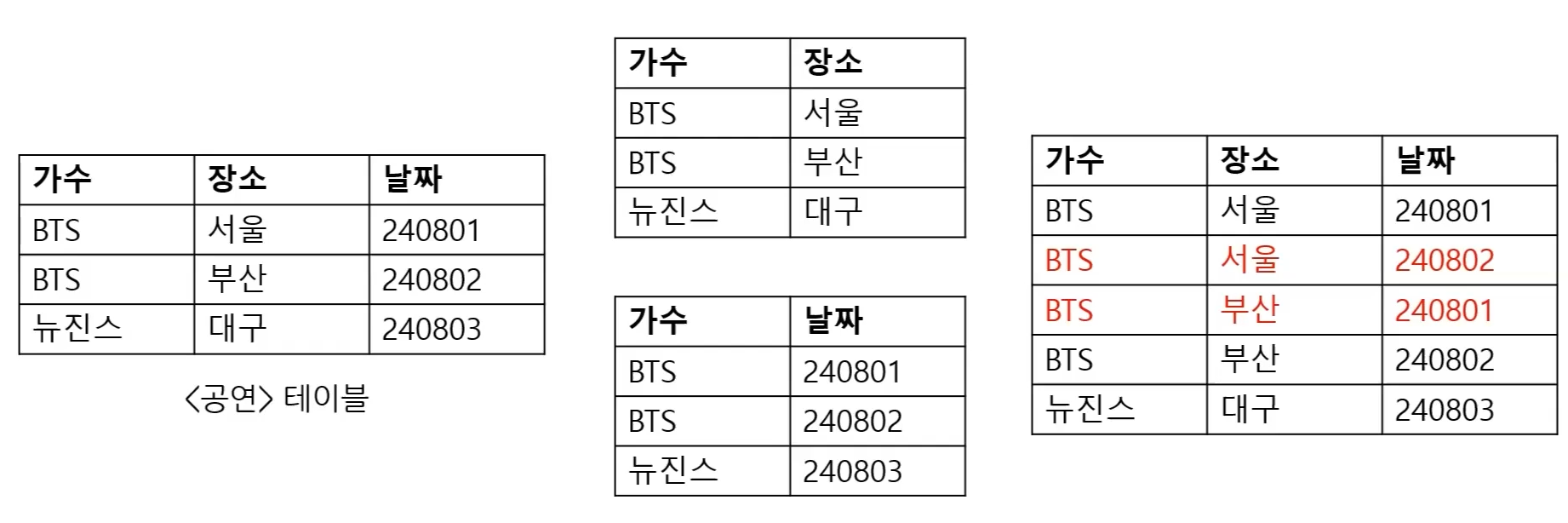

4NF를 만족하면서 후보키를 통하지 않는 조인 종속을 제거
한 릴레이션을 분해하고 다시 합쳤을 대 원본 데이터와 동일하게 복원될 수 잇는경우를 종인 종속이 제거되었다고 함
위 경우는 분해 후 조인 시불필요한데이터가 더 생겨 조인 종속이 제거되지 않음
3개의 테이블로 분리하여 모든 조인 종속성을 제거
매우 철저한데이터 분리를 요구하기에현실적인 DB설계과정에서는필요성이 적음
강의간단요약및느낀점
정규화까지 왔다....정규화는 솔직히 봐도봐도 진짜 모르겠다. 예시만 보면 알듯말듯한데 사실 실제로 쓰이는 데이터는 더 복잡할테니...개념을 제대로 익혀야 할텐데 너무 어렵다ㅜㅜ 문제를 많이 풀어보면 감이 잡힐려나?

'메타코드 > 정보처리산업기사' 카테고리의 다른 글
| [정보처리기사] 메티코드 강의 후기 :: 5강 정보시스템 구축 관리 (0) | 2024.12.30 |
|---|---|
| [정보처리기사] 메티코드 강의 후기 :: 4강_프로그래밍 언어 활용 (0) | 2024.12.22 |
| [정보처리기사 필기정리] 메티코드 강의 후기 :: 2강 소프트웨어 개발 (2) | 2024.12.08 |
| [정보처리기사] 메타코드 강의 후기 :: 1강 소프트웨어 설계 (1) | 2024.12.02 |